
대규모 시스템 설계 기초:01. 사용자 수에 따른 규모 확장성
대규모 시스템 설계 기초 - 01 장을 보고 정리한 내용 입니다. 캐시, CDN, 데이터센터, 데이터베이스 규모 확장 등에 대한 아주 기초적인 내용들을 정리 했습니다.

운영 환경에서 데이터베이스 이중화 시 문제 해결 키워드
키워드
주 데이터베이스 서버가 다운되면 부 서버가 새로운 주 서버가 된다.
이 때 부 서버에 보관된 데이터가 최신 상태가 아닐 수 있는데, 이 때를 위해 복구 스크립트(recovery script) 가 필요하다
다중 마스터(multi-masters) 나 원형 다중화(circular replication) 방식을 도입하면 이런 상황에 대처 할 수 있다
응답 시간 개선
Cache
[!캐시 사용 시 고려사항]데이터 갱신은 자주 일어나지 않지만 참조는 빈번하게 일어나는 경우 고려 해 볼만 함데이터가 제거되어도 문제가 없는 경우 고려 해 볼만 함
만료 정책에 대한 고민 필요
- 만료 기한이 너무 길면 원본과 차이 날 가능성 높음
- 만료 기한이 너무 짧으면 DB Hit 가 자주 일어남
캐시 데이터의 일관성 유지 고민 필요
- 일관성? : 여기서 말하는 일관성은 원본과 사본이 같은지 여부
- 저장소의 원본을 갱신하는 연산과 캐시를 갱신하는 연산은 단일 트랜잭션으로 처리되어야 함. 하지만 이렇지 않을 경우 일관성이 깨질 위험이 있음
- 참고 : https://www.usenix.org/system/files/conference/nsdi13/nsdi13-final170_update.pdf #캐시_일관성
단일 장애지점(Single Point of Failure, SPOF) 고려 필요
- 단일 장애 지점? : 어떤 특정 지점에서의 장애가 전체 시스템의 동작을 중단시켜버릴 수 있는 경우, 해당 지점을 단일 장애 지점이라고 함
- 결과적으로 SPOF 피하려면 캐시 서버를 분산 시켜야 함
캐시 메모리의 크기 고려 필요
- 캐시 메모리가 너무 작으면 엑세스 패턴에 따라 데이터가 밀려나(eviction) 캐시 성능 떨어질 수 있음
- 해결하려면 캐시 메모리를 과할당(overprovision) 하면 됨
데이터 방출(eviction) 정책 고려 필요
- 데이터 방출 정책? 캐시가 꽉 찼을 때 추가로 캐시에 데이터를 넣어야 할 경우 기존 데이터를 내보내야 함. 이것을 캐시 방출 정책이라고 함
- 방출 정책 가운데 가장 널리 쓰이는 것은 LRU(Least Recently Used)
- 마지막으로 사용 된 시점이 가장 오래된 데이터를 내보내는 정책
- 다른 정책으론 LFU(Least Frequently Used)
- 사용된 빈도가 가장 낮은 데이터를 내보내는 정책
- FiFo(First In First Out)
- 가장 먼저 캐시에 들어온 데이터를 내보내는 정책
동적_캐시?
상대적으로 새로운 개념임
- 요청 경로(Request path)
- 질의 문자열(Query string)
- 쿠키(Cookie)
- 요청 헤더(Request header)
- ...
등의 정보를 이용, html 페이지를 캐싱한다
A(ks): 서버에서 해주는 캐싱이 아니라 큰 범위의 캐싱일 수 있지 않을까?
CDN(Content Delivery Network)
[!What is CDN?]
정적 콘텐츠를 전송하는 데 쓰이는, 지리적으로 분산된 서버의 네트워크
정적 콘텐츠: 이미지, 비디오, CSS, JavaScript 등
아래의 그림은 CDN 이 어떻게 동작하는지를 설명한다
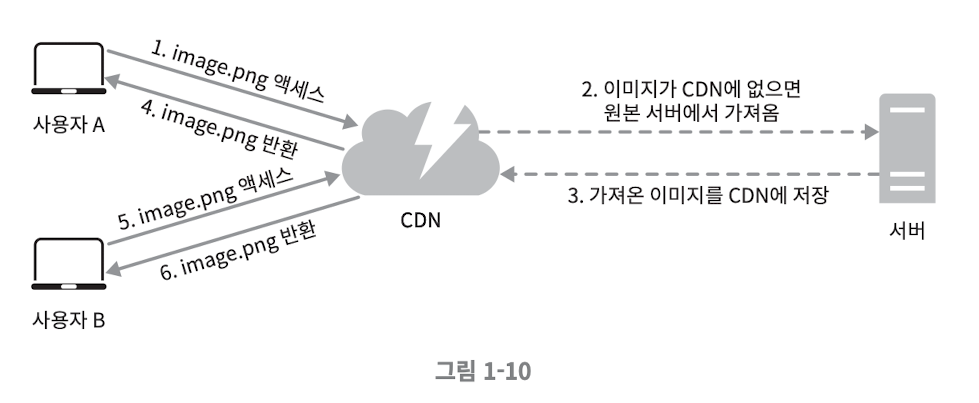
CDN 사용 시 고려 사항
- 비용
- CDN 은 아웃바운드 트래픽에 따라 요금을 책정한다.
- 자주 사용되지 않는 콘텐츠를 캐싱하는것은 이득이 크지 않다.
- 만료 시간의 설정
- 시의성이 중요한 콘텐츠는 만료 시점을 잘 선택해야 한다
- 만료 시간이 너무 길면 콘텐츠의 신선도가 떨어짐
- 만료 시간이 너무 짧으면 원본 서버에 빈번히 접속하게 됨
- 시의성이 중요한 콘텐츠는 만료 시점을 잘 선택해야 한다
- CDN 장애 대처 방안
- CDN 자체가 죽었을 경우 어떻게 동작해야 하는지 고려해야 한다
- 콘텐츠 무효화 방법
- 아직 만료되지 않았더라도 특정 컨텐츠를 CDN 에서 제거할 수 있음
- CDN 서비스 사어자가 제공하는 api 사용
- 콘텐츠의 다른 버전을 서비스 하도록 오브젝트 버저닝(Object versioning) 이용
- 콘텐츠의 새로운 버전 지정은 보편적으로 url 마지막에 버전 번호를 인자로 주면 됨. 예를 들어 image.png?v=2 형태
- 아직 만료되지 않았더라도 특정 컨텐츠를 CDN 에서 제거할 수 있음
CDN 과 Cache 의 혼용
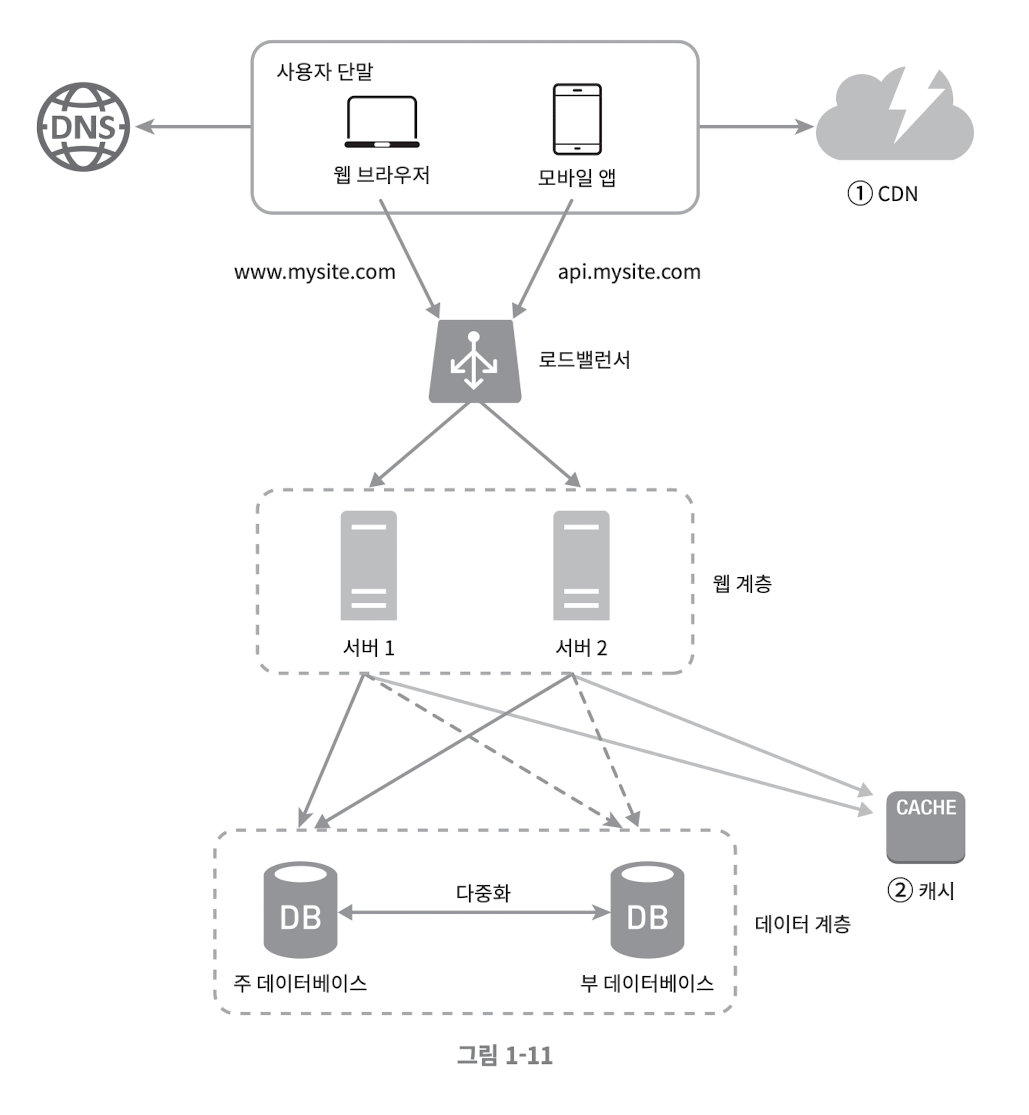
무상태(stateless) 웹 계층
상태 정보가 NoSQL 로 이동하고 웹 서버들로부터 제거 되었으므로 스케일 아웃이 가능 해 졌다
데이터 센터
여러 나라에서 유저에게 쾌적한 환경을 제공하기 위해서는 여러 데이터 센터(Data center) 를 지원하는 것이 필수이다.
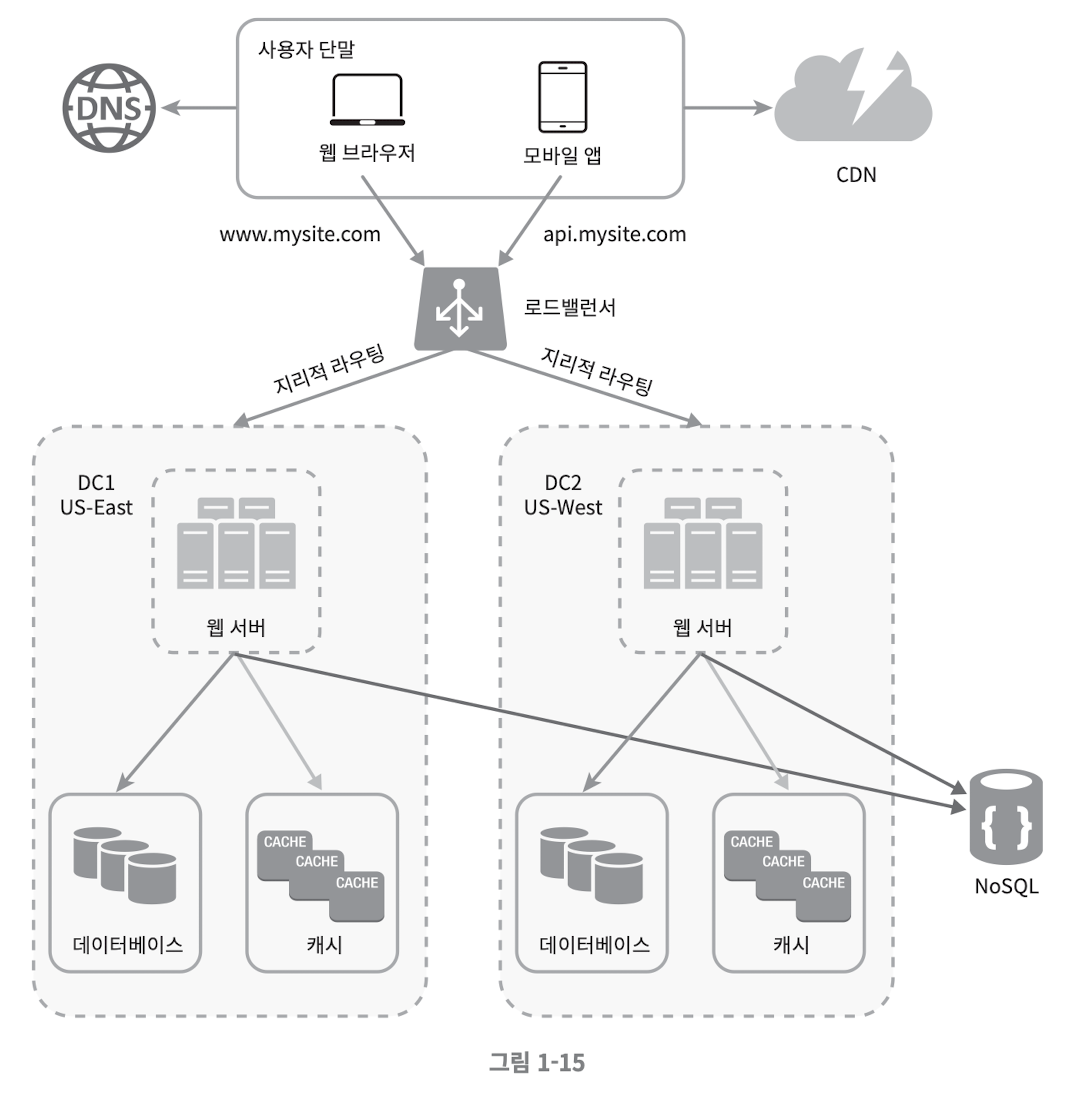
- 지리적 라우팅 (GeoDNS-routing) : 장애가 없는 상황에서 사용자는 가장 가까운 데이터 센터로 접근하는 것
- 지리적 라우팅에서 geoDNS 는 사용자의 위치에 따라 도메인 이름을 어떤 IP 주소로 변환할지 결정 할 수 잇도록 해 주는 DNS 서비스 이다
[! 장애가 발생 한다면?]
만일 위 그림에서 DC2 에 심각한 장애가 발생 하면 모든 트래픽은 장애가 없는 데이터 센터로 전송 된다
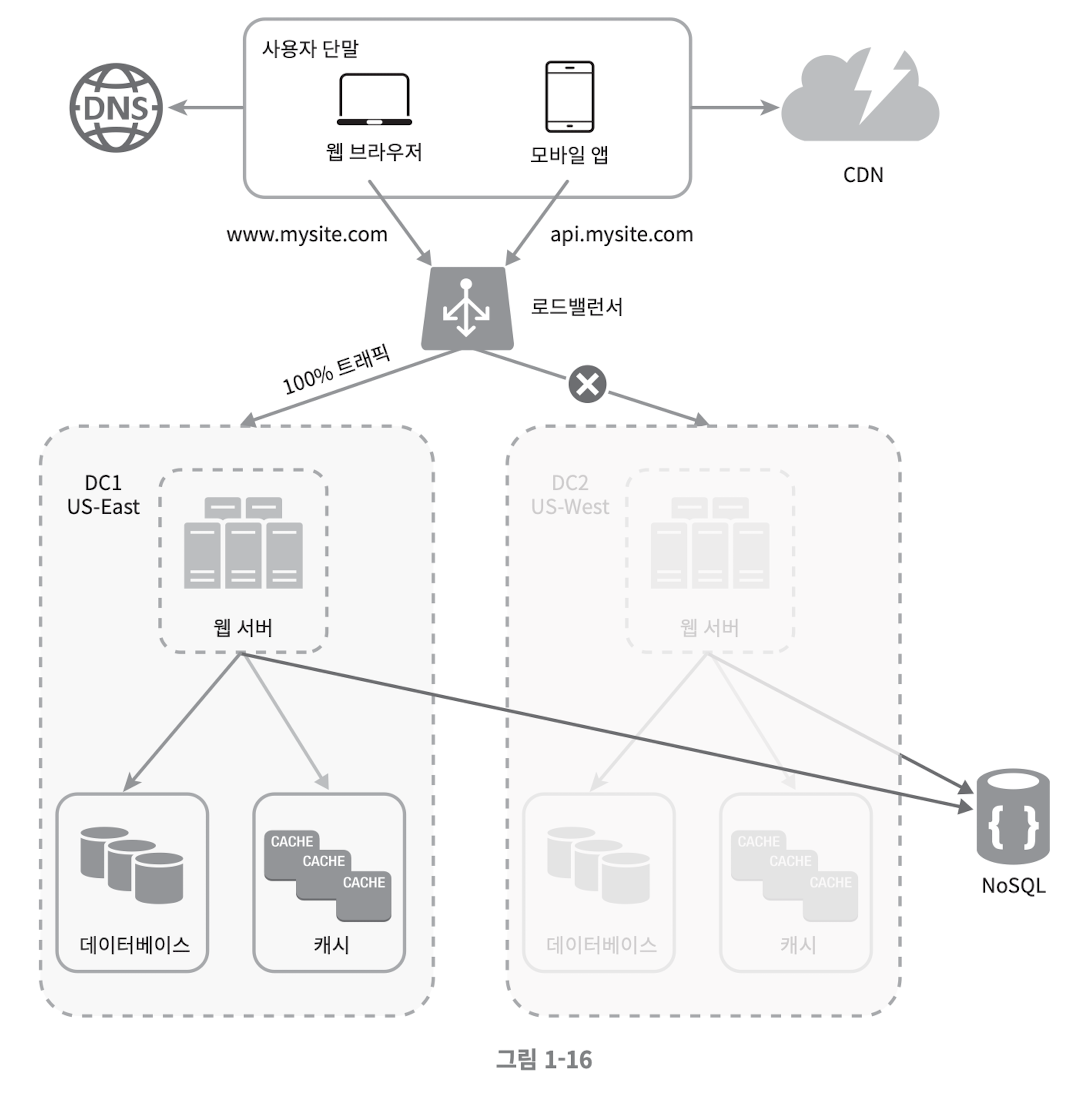
데이터센터 아키텍처 적용 시 고려해야 할 점
- 트래픽 우회 : 올바른 데이터 센터로 트래픽을 보내는 효과적인 방법에 대한 고민 필요
- ex: GeoDNS 는 사용자에게서 가낭 가까운 데이터센터로 트래픽을 보낼 수 있도록 해줌
- 데이터 동기화(Synchronization) : 데이터 센터마다 별도의 데이터베이스가 있다면 동기화의 문제가 생길 수 있음
- 장애가 자동적으로 복구되어(Failover) 트래픽이 다른 데이터베이스로 우회된다 해도 동기화 되지 않았다면 데이터가 없을 수 있음
- 보편적 전략은 데이터를 여러 데이터센터에 걸쳐 다중화 하는 것
- 참고: 기술 블로그: 넷플릭스 - 데이터센터 다중화
- 테스트와 배포(Deployment)
- 애플리케이션의 여러 위치에 따라 테스트가 실패 할 가능성이 있다.
- 날짜 데이터에 대한 처리
- 위치 데이터에 대한 처리
- 가용 서버의 상태에 따라 배포가 정상적으로 이루어지지 않을 가능성도 있으니 자동화된 배포 도구를 사용하는 것이 좋은 선택이다
- 애플리케이션의 여러 위치에 따라 테스트가 실패 할 가능성이 있다.
로그, 메트릭 그리고 자동화
사업 규모가 커지고 나면 메트릭, 자동화에 투자해야 한다
- 로그: 에러 로그를 보고 판단하기 위한 것
- 메트릭
- 사업 현황에 관한 정보 파악 가능
- 시스템의 상태 파악 가능
- 호스트 단위 메트릭: CPU, 메모리, 디스크 I/O 관한 정보
- 종합 메트릭:
- 데이터베이스 계층의 성능
- 캐시 계층의 성능
- 핵심 비즈니스 메트릭
- 일별 능동 사용자(Daily Active User)
- 수익(Revenue)
- 재방문(Retention)
- 자동화
- 생산성을 높이기 위한 도구의 활용
- CI 도구의 적용
메시지 큐, 로그, 메트릭, 자동화 등을 반영하여 수정한 설계안
- 메시지 큐는 각 컴포넌트가 느슨한 결합(Loosely coupled) 될 수 있도록 하고 결함 내성 높임
- 로그, 모니터링, 메트릭, 자동화 등을 지원하기 위한 장치를 추가
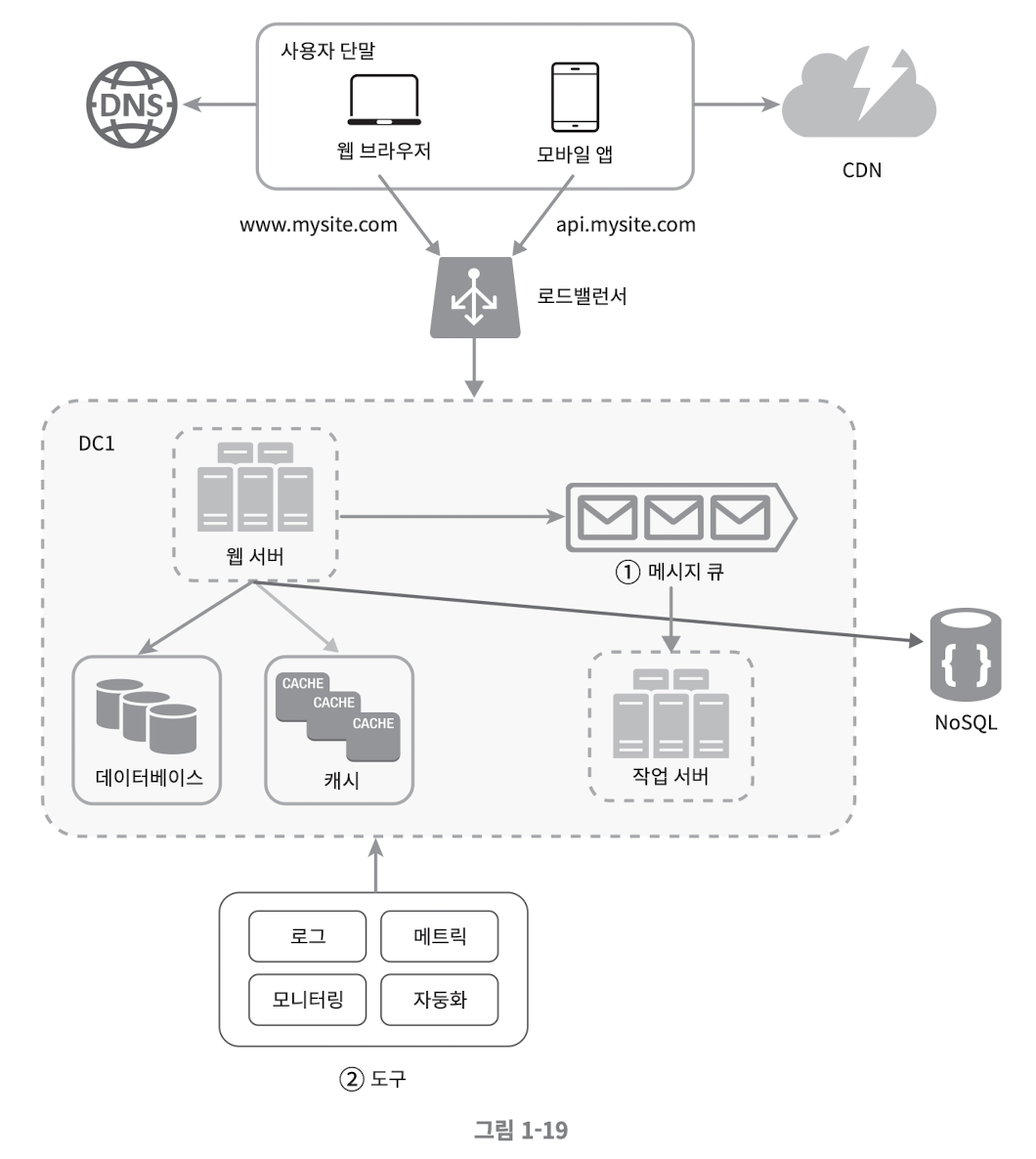
데이터베이스의 규모 확장
데이터베이스의 규모 확장에는 두 가지 접근법이 있음
- 수직적 확장
- 수평적 확장
수직적 확장 (스케일 업)
아마존 RDS(Relational Database Service) 는 24TB RAM 을 갖춘 서버도 상품으로 제공 중
스택오버플로(stackoverflow.com) 는 2013년 한 해 동안 방문 한 천만 명의 사용자 전부를 단 한 대의 마스터 데이터베이스로 처리 하였다.
- 사용자가 계속 늘어나면 한 대 서버로는 결국 감당하기 어렵다
- SPOF(Single Point of Failure) 로 인한 위험성이 크다
- 비용이 많이 든다
수평적 확장 (샤딩)
더 많은 서버를 추가함으로써 성능을 향상시킨다

샤딩은 특정 알고리즘을 통하여 데이터를 분할 저장 하는데, 아래의 예시가 있다
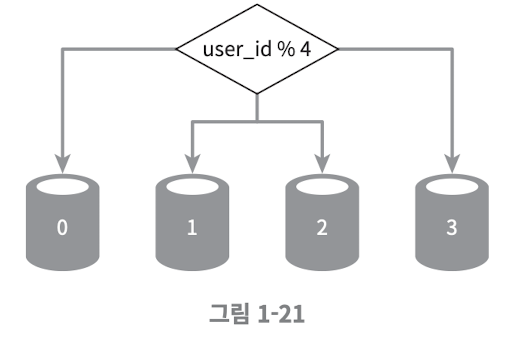
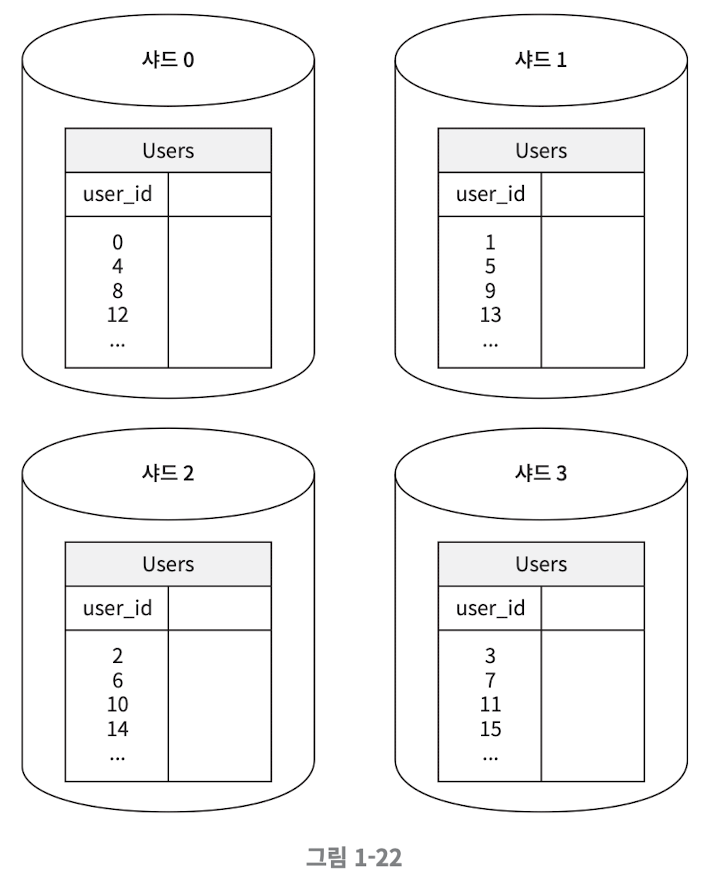
이러한 샤딩 키(Sharding key) 는, 파티션 키(Partition key) 라고도 부르는데, 데이터가 어떻게 분산 될 지 정하는 하나 이상의 컬럼으로 구성 된다
샤딩은 훌륭한 기술이나, 완벽하진 않으며 시스템이 복잡해지고 풀어야 할 새로운 문제도 생긴다
- 데이터의 재 샤딩(Resharding)
재 샤딩은 다음과 같은 경우에 필요 하다- 데이터가 너무 많아져서 하나의 샤드로는 감당하기 어려울 때
- 샤드 간 데이터 분포가 균등하지 못하여 어떤 샤드에 할당 된 공간 소모가 다른 샤드에 비해 빨리 진행될 때
여기서2번 의 경우는 샤드 소진(Shard exhausion) 이라고도 부르며 대안으로는 아래의 방법이 있다
- 샤드 키를 계산하는 함수의 변경
- 데이터 재배치
샤드 소진은 [[안정 해시]] 를 통해 해결 할 수 있다 - 유명인사(Celebrity) 문제
이 문제는 핫스팟 키(Hotspot key) 라고도 부른다.
특정 샤드에 질의가 집중되어 서버에 과부하가 걸리는 문제
만일 유명한 사람들이 하나의 샤드 그룹에 속한다고 하고, 이 데이터를 통해소셜 네트워킹 서비스를 구축하게 되면 해당 샤드 그룹으로의 질의가 많아져서 Read 연산에 과부하가 걸릴 가능성이 있다 - 조인과 비정규화(Join and de-normalization)
하나의 데이터베이스를 여러 샤드에 걸친 데이터를 조인하기 힘들어진다
비정규화를 통해해결 할 수는 있지만 근본적인 해결 방법은 아니다
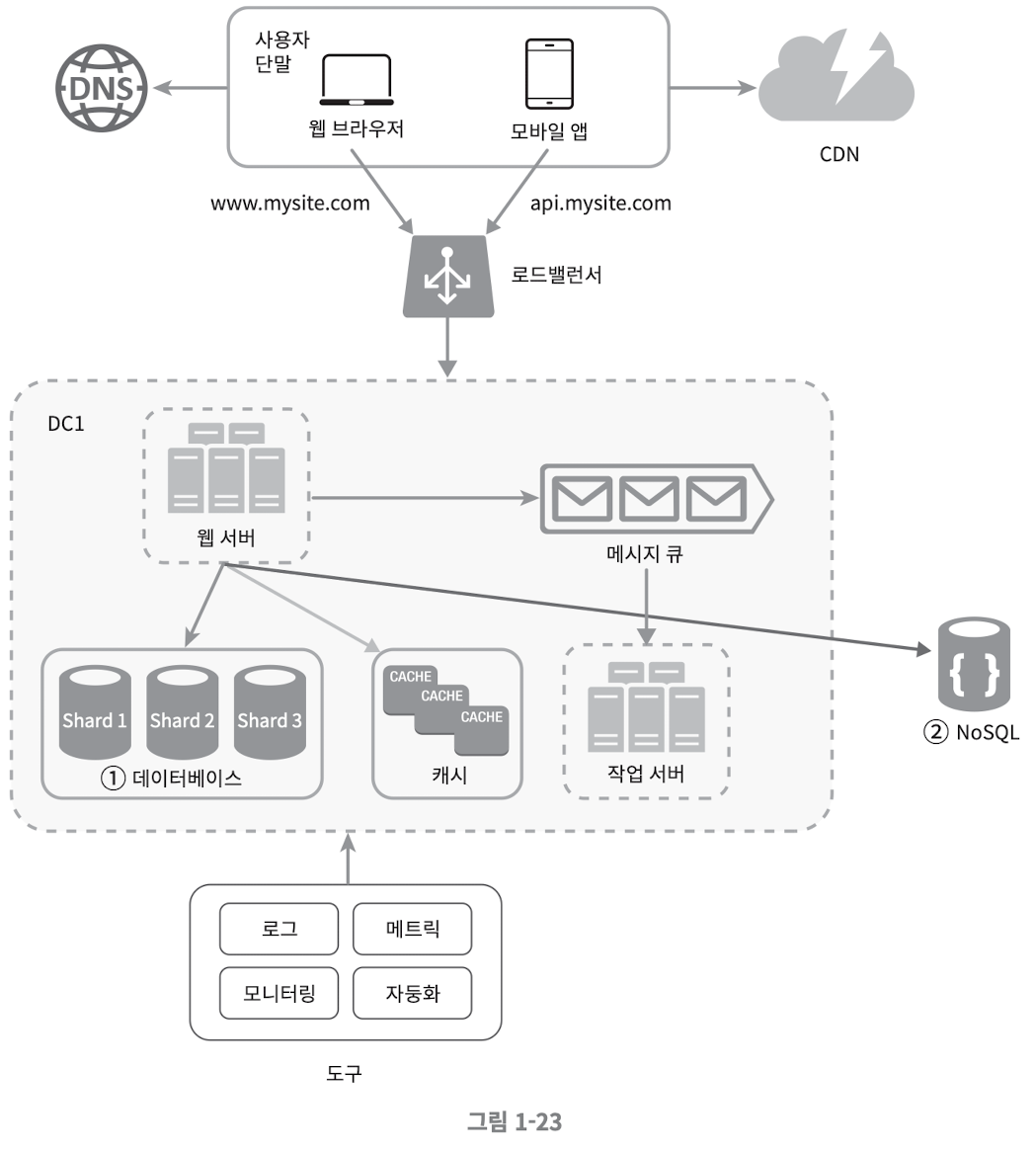
백만 사용자, 그리고 그 이상
시스템의 규모 확장을 위한 정리
- 웹 계층은 무상태 계층으로
- 모든 계층에 다중화 도입
- 가능한 한 많은 데이터를 캐시 할 것
- 여러 데이터 센터를 지원할 것
- 정적 콘텐츠는 CDN을 통해 서비스
- 데이터 계층은 샤딩을 통해 그 규모를 확장
- 각 계층은 독립적 서비스로 분할
- 시스템의 지속적 모니터링과 자동화 도구 활용